At-Memory Architecture - The Key to AI Inference Performance
Untether AI was created to address the key compute and efficiency bottleneck for AI workloads - memory access and data movement. Our at-memory compute architecture breaks the bottleneck, dramatically improving performance and reducing power consumption.
Bringing AI Compute Power
to the Data
As AI applications are exploding, the performance requirements for neural networks are doubling every 3.5 months. As this occurs, the vast amount of data being computed has overrun the capabilities of system and silicon resources that use the classic von Neumann architecture.
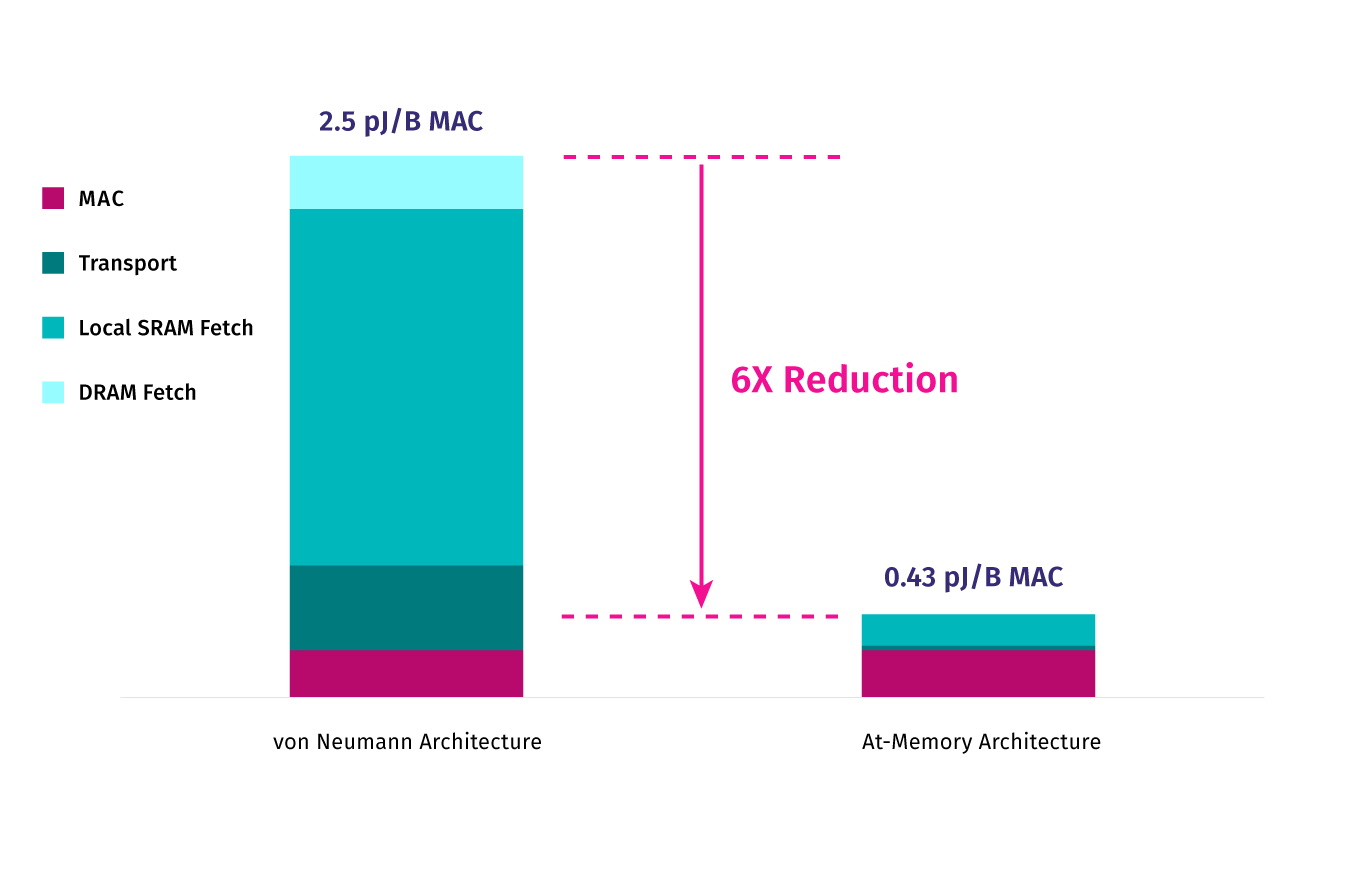
More than 90 percent of the power consumption in AI workloads is from the movement of data. Untether AI has invented a way to move the compute element to where the data is stored, reducing the power consumption for data transfer by six times. This is the fundamental innovation that allows us to provide unprecedented compute density, untethered to traditional approaches.
An Architecture for a New Breed of AI Computing
At Untether AI, we rewrote the rules for compute architectures. Designed from the ground up for AI inference workloads, the runAI® 200 architecture provides best-in-class performance for running deep neural networks;
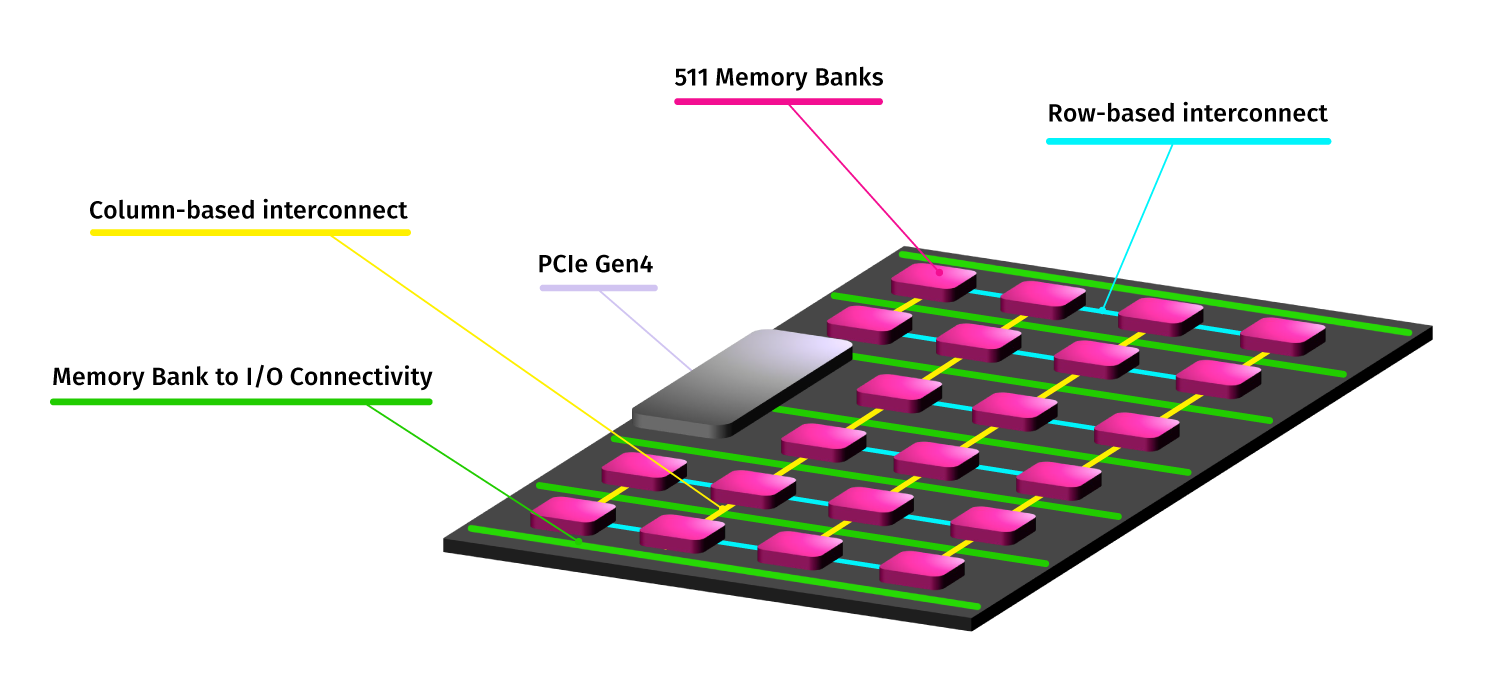
At the heart of the unique at-memory compute architecture is a memory bank: 385KBs of SRAM with a 2D array of 512 processing elements. With 511 banks per chip, each device offers over 200MB of memory, enough to run many networks in a single chip. And with the multi-chip partitioning capability of the imAIgine® Software Development Kit, larger networks can be split apart to run on multiple devices, or even across multiple tsunAImi® accelerator cards.
Learn More About Untether AI Devices and Cards

speedAI240 Devices
With 1,400 custom RISC-V processors in our unique at-memory architecture, these devices deliver up to 2 PetaFlops of inference performance and up to 20 TeraFlops per watt.
See our AI inference acceleration devices
speedAI240 Slim Accelerator Card
The speedAI240 Slim Accelerator Card’s low-profile, 75-watt TDP PCIe design sets the standard as the most efficient edge computing solution, delivering optimal performance and reduced power consumption for various end applications.
See our AI inference accelerator cards