
Record-Breaking MLPerf® Benchmarks
Untether AI achieves industry-leading performance and energy efficiency in MLPerf® Inference benchmarks.
Untether AI Results
In the MLPerf® Inference v4.1 Datacenter and Edge benchmarks, Untether AI demonstrated the highest performance, lowest latency, and best energy efficiency on the Image Classification benchmark ResNet-50 v1.5.
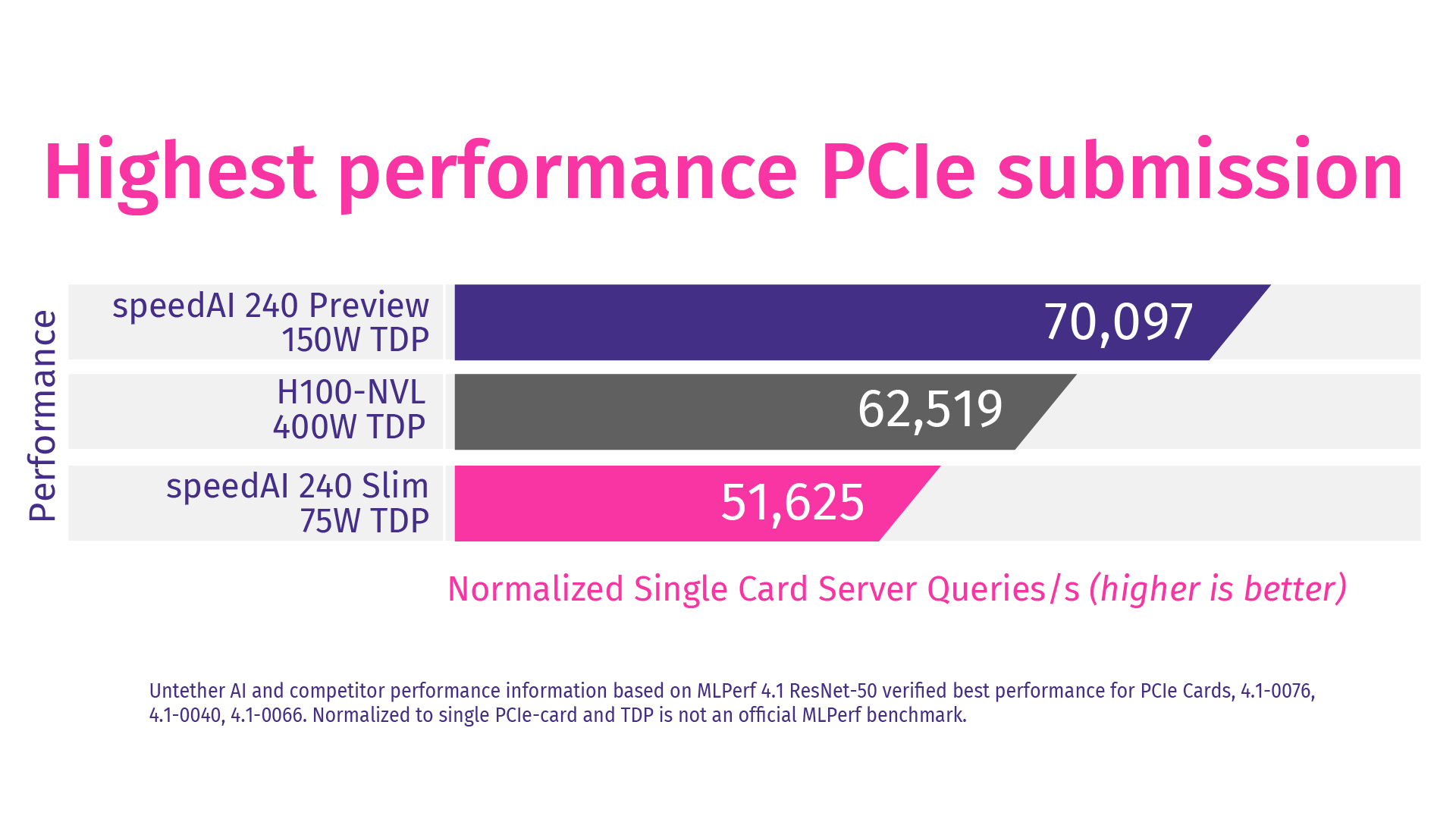

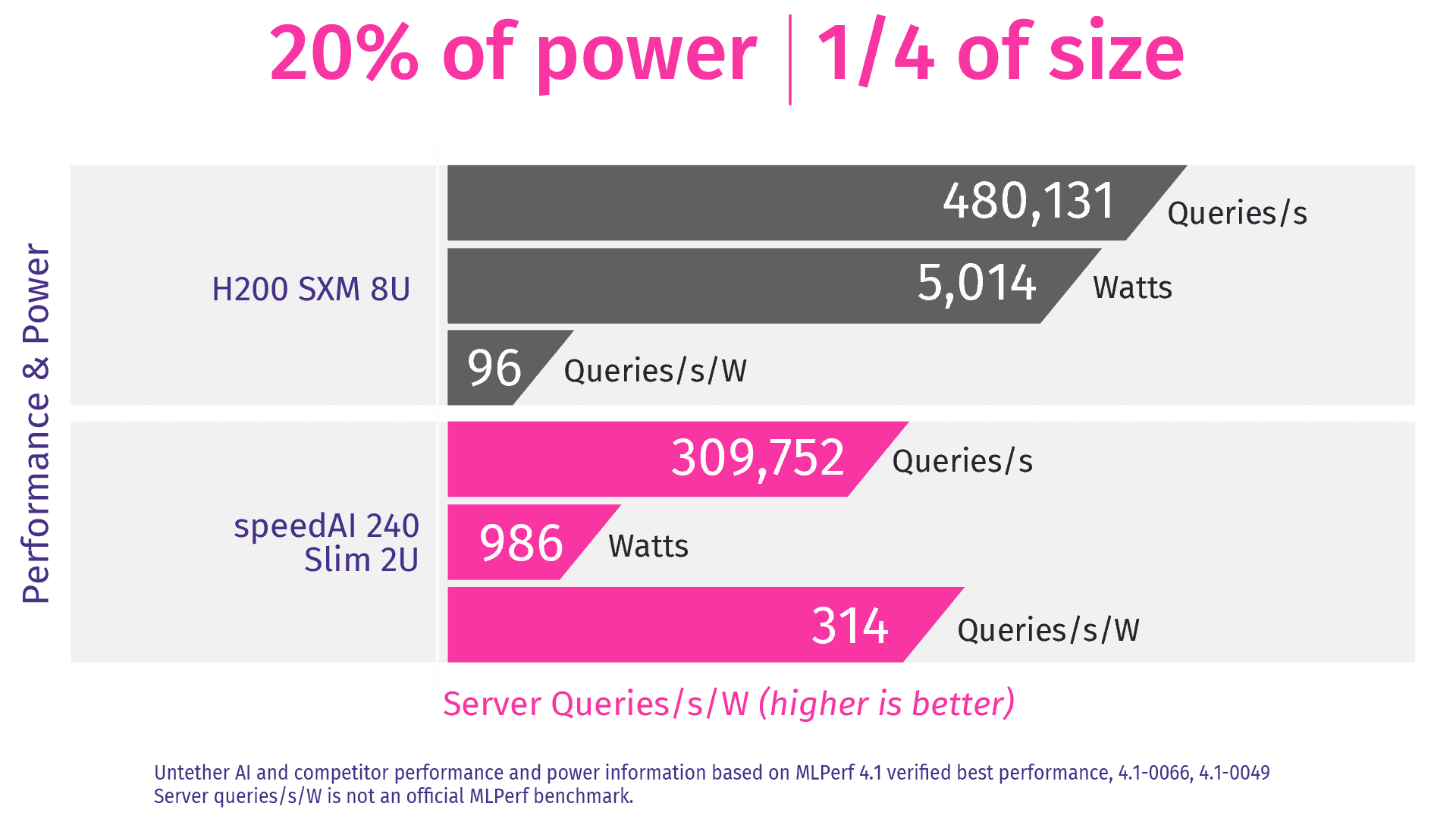


Peak Performance Meets Unmatched Efficiency
The increasing demands of AI are exceeding the capabilities of current system and silicon architectures. As demonstrated in MLPerf® benchmarks, Untether AI delivers world record performance with our At-Memory architecture, scalable accelerators, and automated software tool flow, all while keeping energy consumption to a minimum.
Explore our groundbreaking compute architecture and see what’s possible when untethered from traditional approaches.
Explore NowAI Inference Cards
Power consumption and ownership costs are crucial in AI deployment. Untether AI’s speedAI®240 Slim accelerator cards offer unmatched performance with outstanding power and cost efficiency, even for the most demanding inference tasks. Elevate your edge AI computing with a solution that sets the benchmark for efficiency and capability.
Available Now
imAIgine SDK:
The Window Into Silicon
The imAIgine® Software Development Kit (SDK) provides an automated path to running neural networks on Untether AI’s inference acceleration solutions. Featuring a robust model garden, automated compilation, and advanced analysis tools, users can effortlessly deploy their models and maximize AI performance on the revolutionary speedAI family of devices.
Join our exclusive Early Access Program
What is MLPerf®?
MLPerf® benchmarks – developed by MLCommons Association, measure the performance of hardware platforms, software frameworks, and other services used for AI training and inference. Developed and continuously updated by a consortium of AI researchers and developers, MLPerf® helps developers compare and assess the latest advancements in AI technology.
The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
Visit MLCommons to learn more